Lec 5: Policy Optimization I
Value-based RL versus Policy-based RL
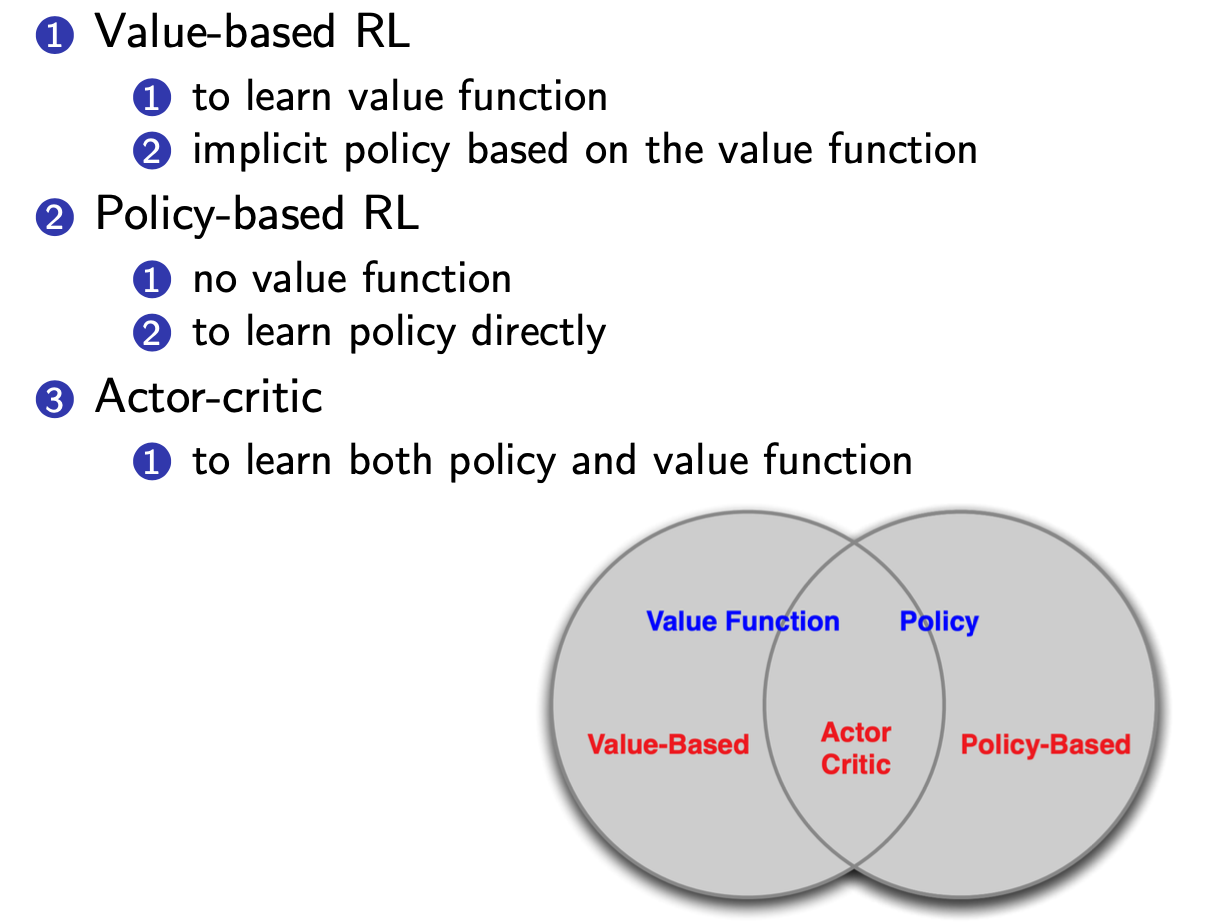
Policy-based RL的优势

Two types of policies:
- Deterministic
- Stochastic
value-based RL learns a deterministic policy
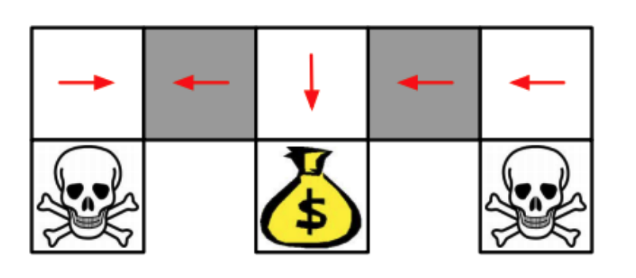
Policy-based RL can learn the optimal stochastic policy
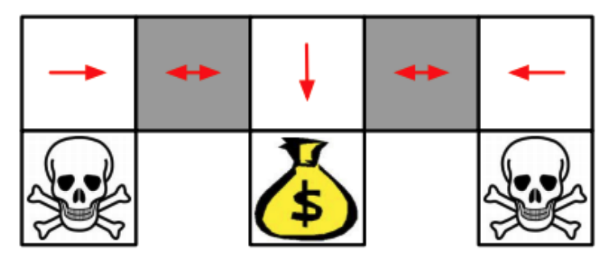
原因在于policy-based RL输出概率
policy-based RL目的在于极大化随机采样的奖励
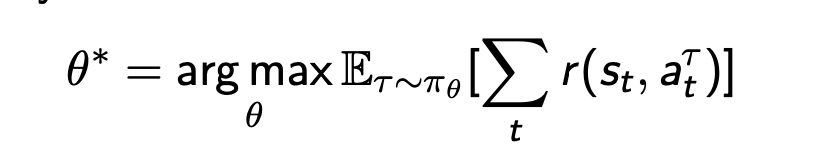
优化方法
- 可导:
- Gradient accend
- 不可导:
- Cross-Entrophy:每次取前10%,让总体分布接近这10%(argmax)
-
Finite Difference:加\epsilon的扰动,算出梯度的近似
-
score function
- 使得 Policy Gradient 的优化与dynamic transition无关
-
使用蒙特卡洛的方法来计算gradient
-
鼓励policy获得更高的分数
m-c方法的优缺点
-
Unbiased but very noisy
-
解决方法:
- Use temporal causality,与后期采取的动作无关
- Use a baseline,G_{t} \Longrightarrow (G_{t} - b(s_{t})),Variance降低
但是G(t)其实是采样得到的,于是可以直接近似估计G(t),于是引入critic
Actor-Critic Policy Gradient

优化

然后可以使用神经网络代替Actor和Critic
Extension
- A2C, A3C
- TRPO
- PPO