Lecture 4: Value Function Approximation
RL从小规模到大规模
- 状态数指数级增长

- 少量状态可以用
lookup table来表示特征,大量状态无法装入内存,同时无法学习如此大量的状态
函数近似
- 避免明确学习每一个状态
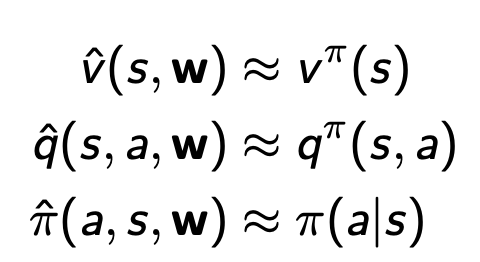
- 通过已见到的状态估计未见到的状态
函数近似的几种情况
- 线性拟合【可微分】-->【梯度下降】
- 神经网络【可微分】-->【梯度下降】
- 决策树
- K近邻
梯度下降
- 在线性拟合的情况下
局部最优自动成为全局最优
Model-free情况下value函数近似
- 没有ground truth,只有rewards

强化学习中的不稳定因素
- 近似函数:引入误差
- bootstrapping:根据先前的经验估计而不是完全依赖新的reward
- off-policy:训练用函数和实际update的函数不同
Why deep neural networks
- 自动提取特征
- 非线性函数拟合
Deep Q-Networks
优化方法

-
experience replay
-
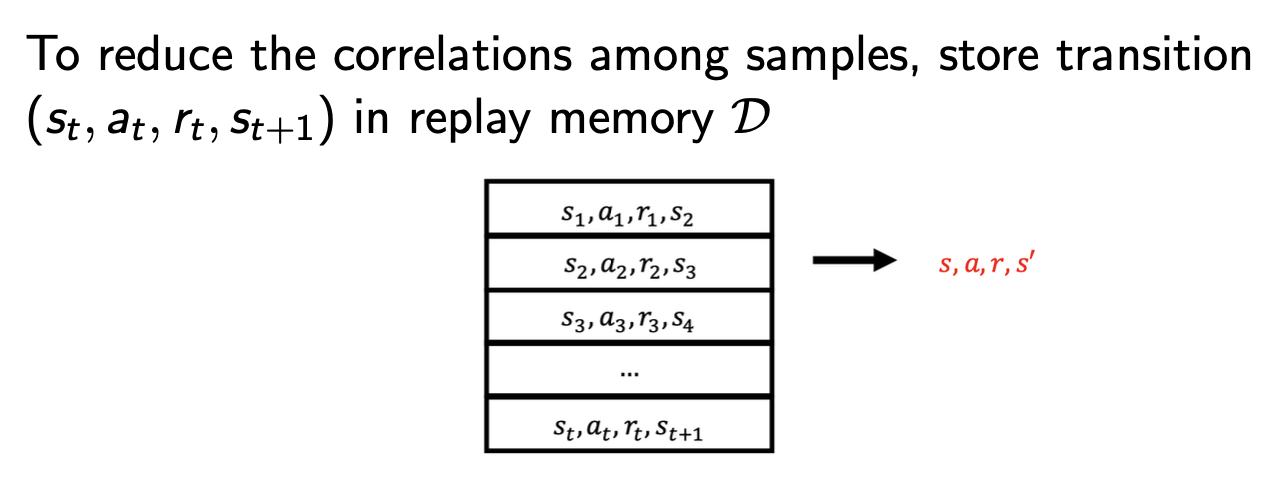
-
fixed targets
-
改善稳定性

#### Abalation Study
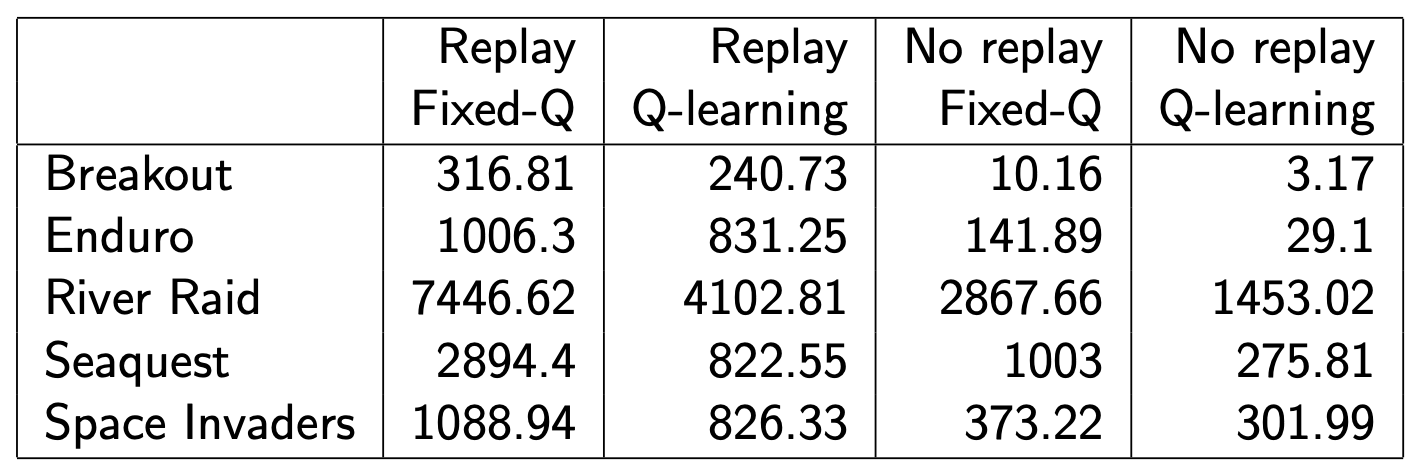
DQN 总结
