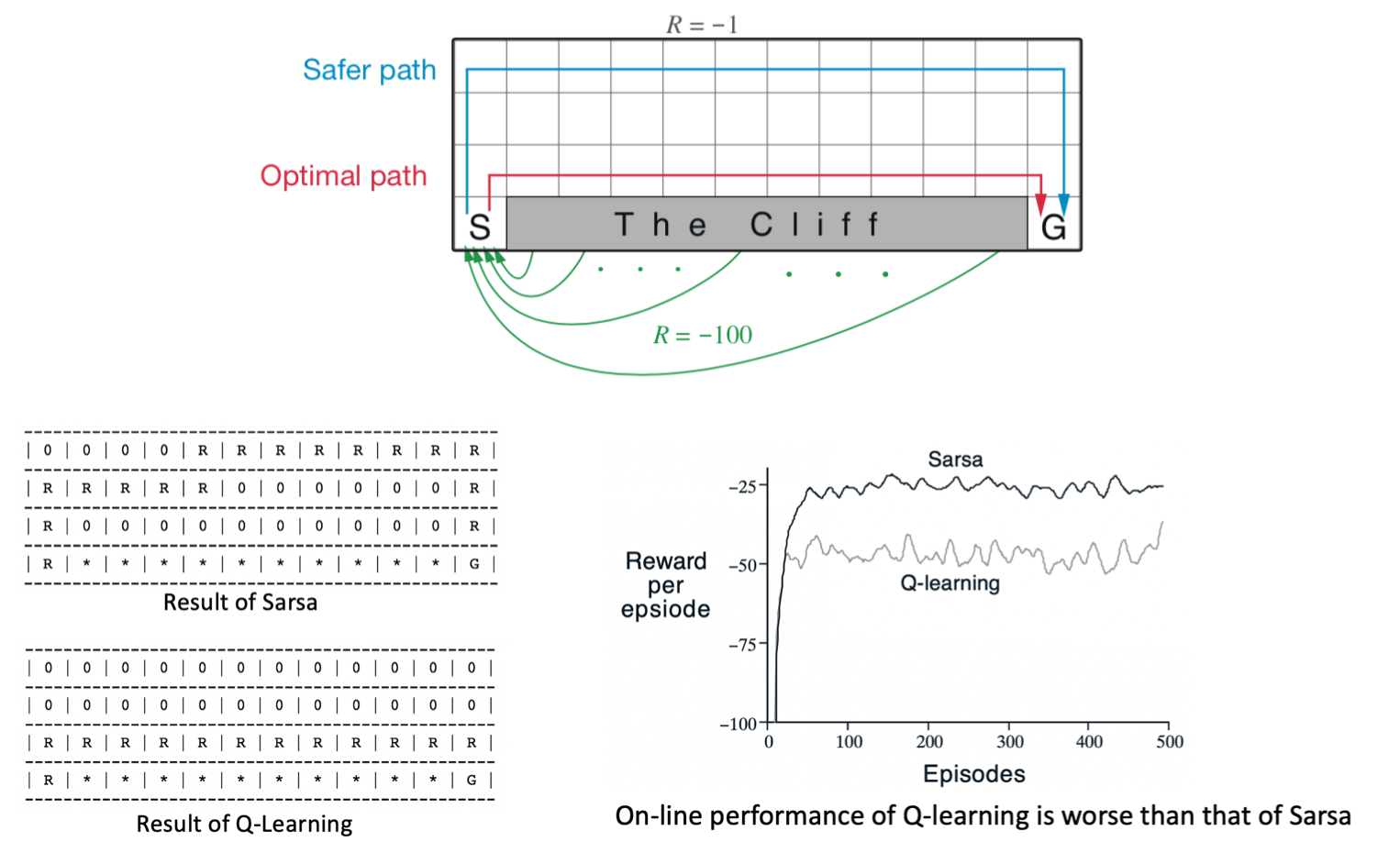
Lecture 3: Model-free Prediction and Control
Model-Free RL:
Model-free: solve an unknown MDP
In a lot of real-world problems, MDP model is either unknown or known by too big or too complex to use
- Atari Game, Game of Go, Helicopter, Portfolio management, etc
Model-free RL can solve the problems through interaction with the environment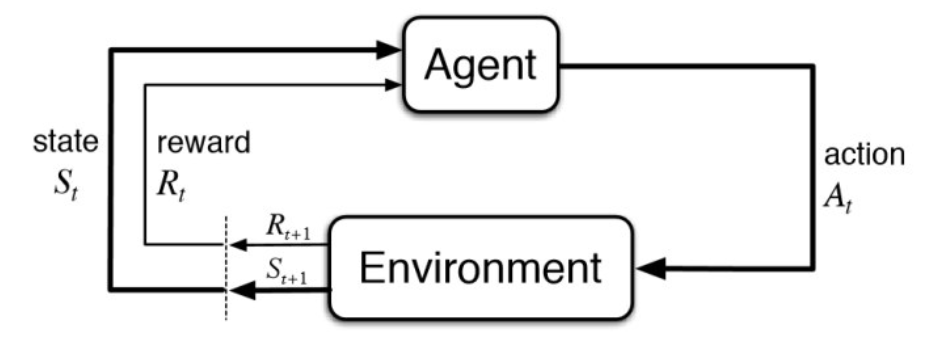
How to do policy evaluation:
- Monte Carlo policy evaluation(采样)
- Temporal Difference (TD) learning
Monte Carlo policy evaluation

更方便的方法:
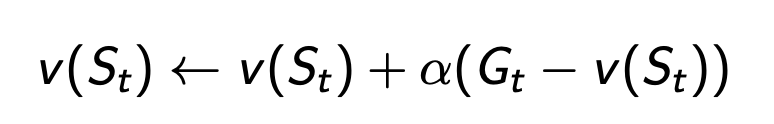
MC & DP
MC --> model free,DP --> require MDP
MC --> fast
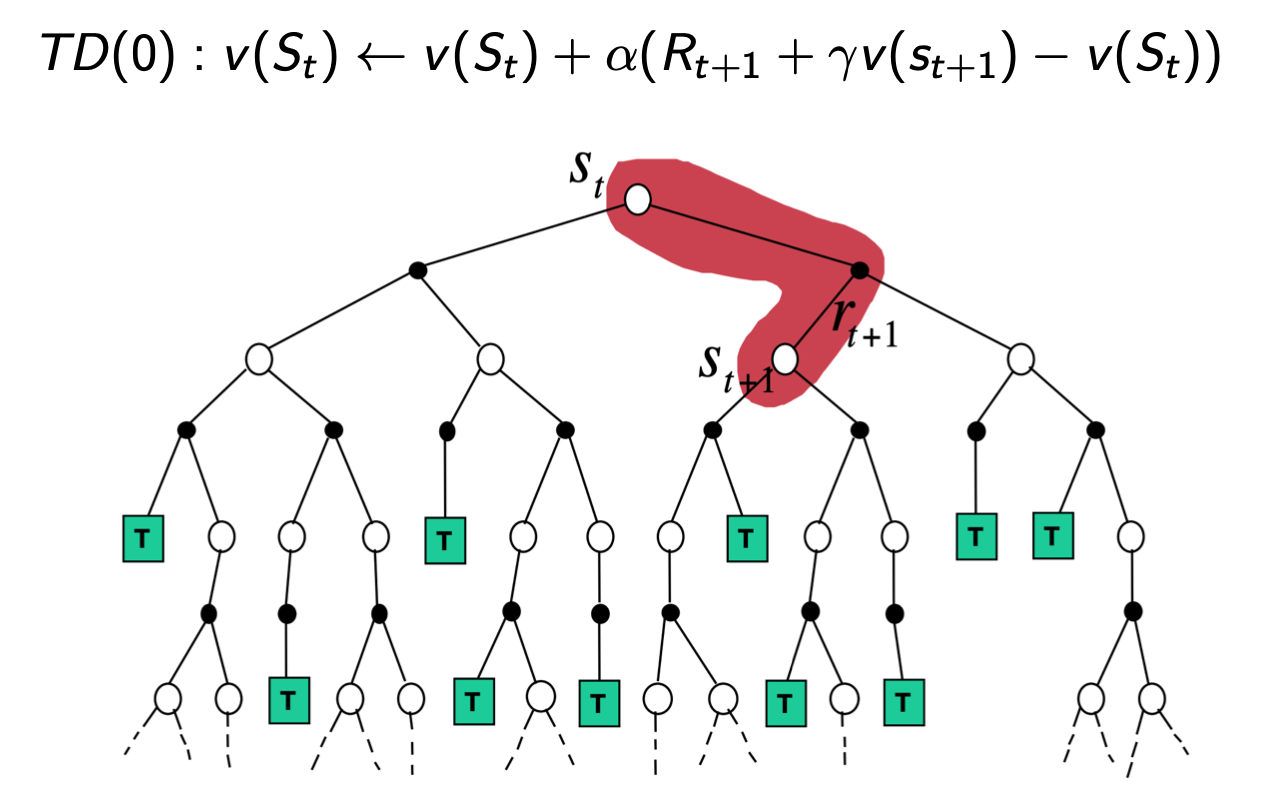
Temporal Difference (TD) learning
TD learns from incomplete episodes, by bootstrapping
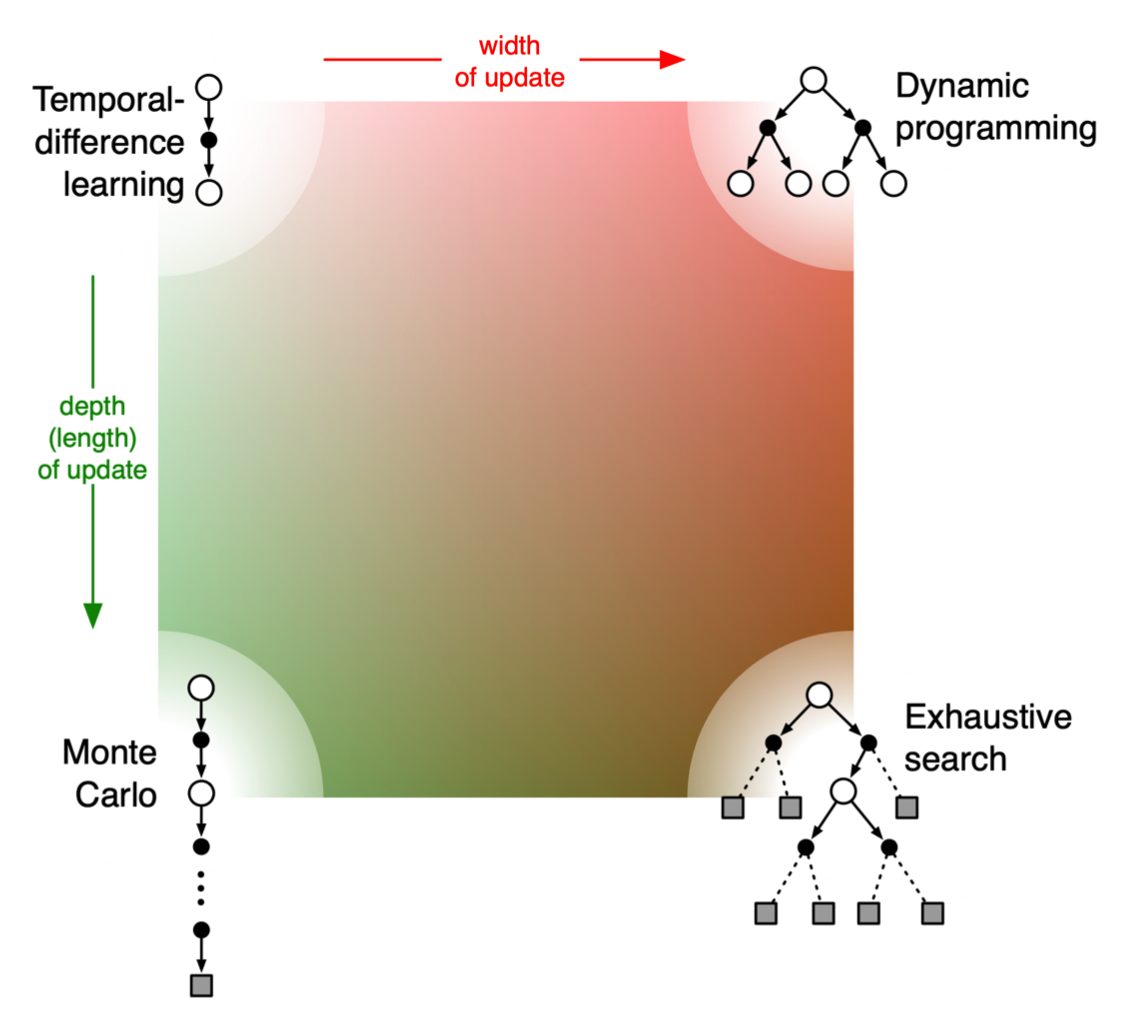
DP,MC,TD的区别
DP
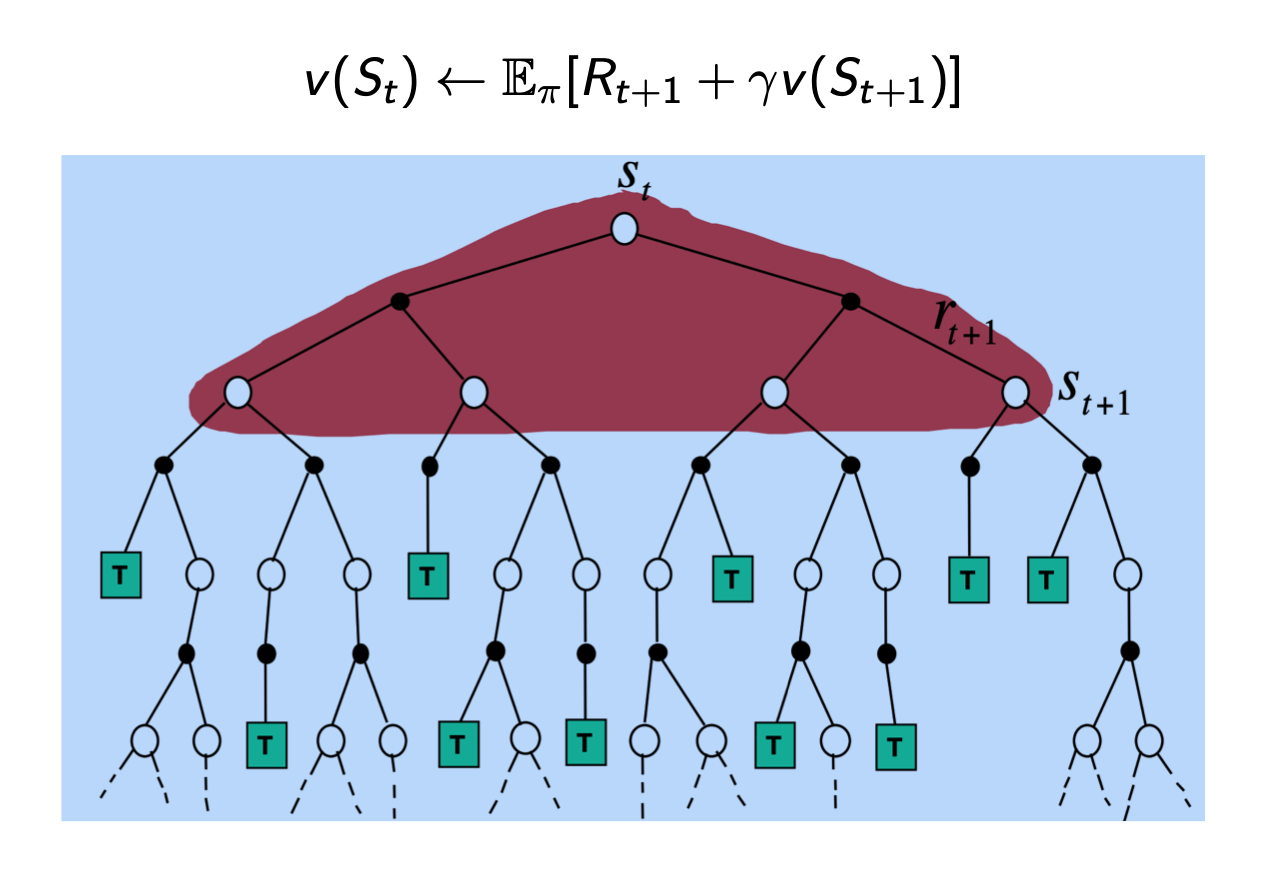
MC
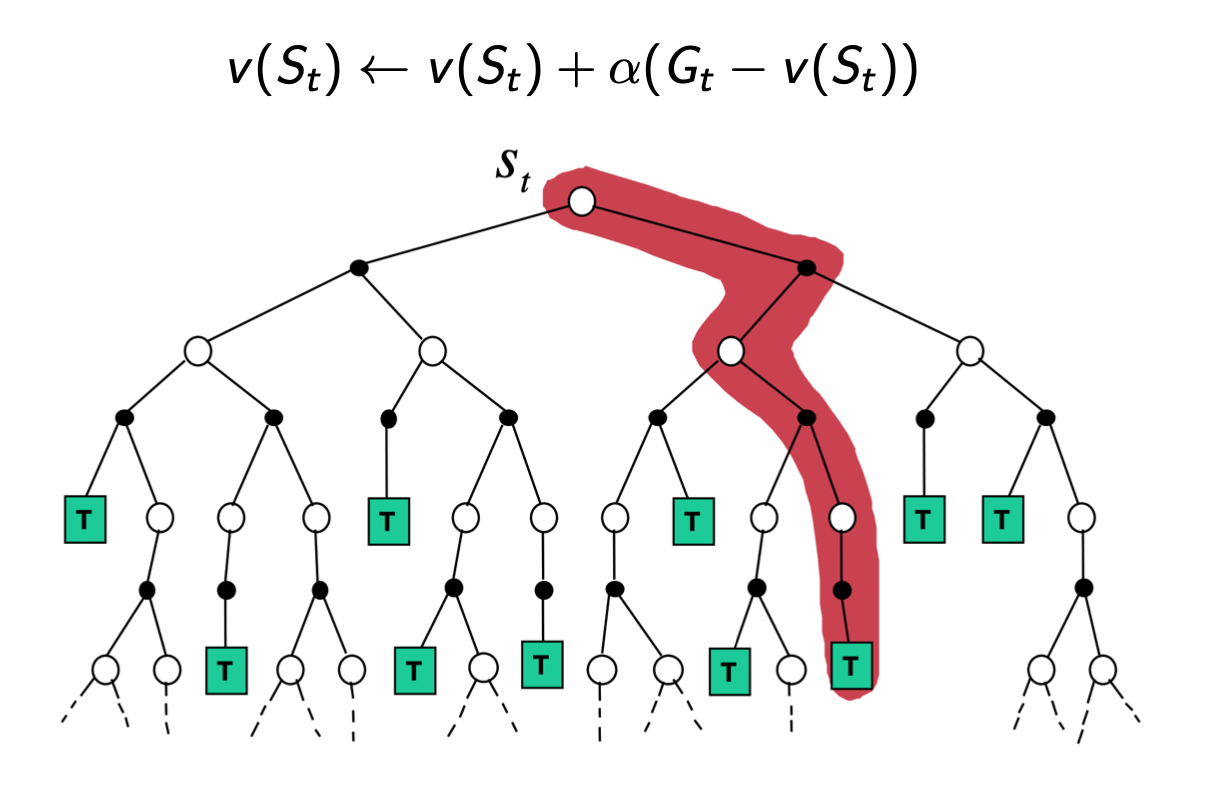
TD
综合比较
Model-free Control for MDP
\epsilon-Greedy: ensure exploration

Monte Carlo with ε-Greedy Exploration

On-policy learning & Off-policy learning
On-policy: 使用一个策略进行探索/学习

Q learning